Mối nguy hiểm khi trí tuệ nhân tạo bị đánh lừa
- Nga công bố UAV mới sử dụng trí tuệ nhân tạo
- Ấn tượng với du thuyền được trang bị trợ lý ảo trí tuệ nhân tạo
- Bộ Quốc phòng Mỹ phác thảo chiến lược trí tuệ nhân tạo
Những kỹ thuật đơn giản đánh lừa AI
Giả định, đó là năm 2022. Bạn đang lái chiếc ô tô tự hành chạy dọc theo con đường quen thuộc hàng ngày trong thành phố. Rồi chiếc ô tô dừng lại trước cột đèn tín hiệu giao thông mà nó đã lướt qua hàng trăm lần trước đó. Nhưng, lần này có khác: chiếc xe bỗng nhiên không chịu dừng lại mà vẫn tiếp tục lao về phía trước.
Đối với bạn, đèn đỏ báo hiệu như bao lần trước nhưng với chiếc xe thì vấn đề khác hẳn. Bởi vì, vài phút trước đó có kẻ xấu nào đó lén lút dán một sticker nhỏ lên trên cột đèn tín hiệu mà bạn cũng như chiếc xe không hề nhận biết.
 |
| Những chiếc ô tô tự hành trang bị AI sẽ là mục tiêu "tấn công đánh lừa" của hacker trong tương lai không xa. |
Sticker nhỏ đến mức mắt thường không thể nhìn thấy nhưng đủ lớn để đánh lừa công nghệ nhận dạng trên chiếc ô tô tự hành khiến nó không "nhìn thấy" đèn tín hiệu đã chuyển sang màu đỏ. Đó là cách hết sức đơn giản để đánh lừa trí tuệ nhân tạo (AI).
Khi mà các thuật toán máy học (machine learning) đang ngày càng được ứng dụng sâu rộng trên đường phố, hệ thống tài chính cũng như y tế, các nhà khoa học máy tính luôn nỗ lực tìm ra cách bảo vệ chúng chống lại những cuộc tấn công theo kiểu "đối đầu" như đã đề cập ở trên trước khi thủ đoạn lừa bịp trở thành hiện thực.
Daniel Lowd, phó giáo sư khoa học máy tính và thông tin Đại học Oregon (Mỹ), bình luận: "Mối lo ngại đang ngày một tăng trong thế giới máy học và AI, nhất là khi các thuật toán ngày càng được sử dụng rộng rãi hơn. Nếu như thư rác có thể vượt qua được phần mềm nhận dạng hay một vài email bị chặn thì điều đó chẳng là vấn đề đáng sợ. Tuy nhiên, khi bạn đang phụ thuộc vào hệ thống nhận dạng trong chiếc ô tô tự hành hiện đại để biết rõ hành trình và tránh va đụng những phương tiên giao thông khác thì vấn đề trở nên cực kỳ nguy hiểm".
 |
| Daniel Lowd, phó giáo sư khoa học máy tính và thông tin Đại học Oregon (Mỹ). |
Khi một cỗ máy thông minh bị rối loạn hay bị hacker tấn công chiếm quyền điều khiển, các thuật toán máy học sẽ "nhìn" thế giới theo cách khác - nghĩa là, một con gấu trúc có thể trông giống như con vượn hoặc chiếc xe buýt chở học sinh biến thành con đà điểu khổng lồ!
Trong một thử nghiệm, một nhóm nhà nghiên cứu người Pháp và Thụy Sĩ chứng minh được rằng các thuật toán bị rối loạn do "tấn công đánh lừa đối đầu" sẽ khiến cho hệ thống máy tính nhìn thấy con sóc thành ra con cáo xám, hay tách cà phê thành… con vẹt đuôi dài Nam Mỹ!. Ví dụ như một đứa trẻ đang học cách nhận biết những con số.
Khi đó, đứa trẻ sẽ học cách nhận biết những con số một cách nhanh chóng theo đặc điểm riêng biệt: số 1 cao và mảnh mai, số 6 và 9 có thòng lọng to trong khi số 8 có đến 2 thòng lọng và cứ thế. Kế đến, đứa trẻ học cách nhận biết nhanh các con số 4, 8 hoặc 3 bất chấp chúng được viết theo kiểu nào mà nó chưa được nhìn thấy trước đó.
Trở lại câu chuyện, các thuật toán máy học cũng được học cách nhìn thế giới thông qua tiến trình tương tự như đứa trẻ. Nghĩa là, hàng trăm hoặc hàng ngàn ví dụ mẫu (thường được dán nhãn cụ thể) được các nhà khoa học nạp vào máy tính để nó học hỏi cách nhận biết mọi thứ. Nhờ vào dữ liệu đồ sộ này, máy tính nhận biết được con số hay vật thể gì đó qua đặc điểm riêng biệt.
Từ đó, máy tính có thể nhìn vào một tấm hình và tuyên bố chắc nịch "đó là số 5!" với độ chính xác cao. Theo cách đó, đứa trẻ và máy tính học được cách nhận dạng những con số cũng như hàng loạt vật thể khác nhau - từ con mèo cho đến chiếc thuyền và gương mặt người.
Nhưng, không giống như đứa trẻ, máy tính dù được trang bị AI vẫn không thể chú ý đến những chi tiết nhỏ nhặt như là cái tai lông lá của con mèo hay góc cạnh đặc trưng của con số 4. Bởi vì, bất chấp AI, nó không biết nhìn bức tranh toàn cảnh như con người. Mà thay vào đó, máy tính chỉ biết nhìn các pixel riêng biệt của hình ảnh một cách nhanh nhất có thể để nhận biết vật thể.
Nếu như tuyệt đại đa số con số 1 có một pixel màu đen tại một vùng đặc biệt và vài pixel màu trắng ở vùng đặc biệt khác, lúc đó máy tính sẽ đưa ra đáp án cuối cùng sau khi kiểm tra một vài pixel này.
Trở lại với tín hiệu đèn đỏ. Với vài thao tác điều chỉnh pixel hình ảnh - hay gọi theo các chuyên gia là "sự gây nhiễu loạn" - thì lúc đó máy tính tưởng nhầm đèn đỏ là thứ gì đó khác. Đó là yếu điểm được đối tượng xấu khai thác.
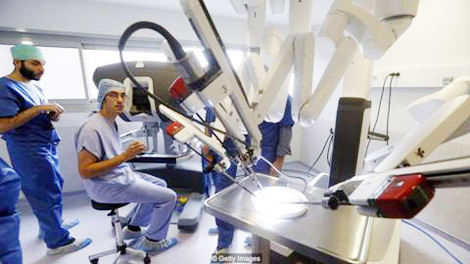 |
| Những robot phẫu thuật sử dụng AI cũng có thể bị hacker chiếm quyền điều khiển. |
Theo kết quả một nghiên cứu được thực hiện tại Phòng thí nghiệm Trí tuệ Nhân tạo Tiến hóa Đại học Wyoming và Đại học Cornell với sự tạo ra một loạt các ảo ảnh thử thách AI. Các hình ảnh vật thể và màu sắc trừu tượng gây ảo giác này không hề có ý nghĩa gì đối với con người song máy tính nhanh chóng phán đoán đó chính là những con rắn hay các khẩu súng trường. Điều đó cho thấy sự nhận biết của AI có thể bị đánh lừa dẫn đến nhầm lẫn tai hại. Đây cũng chính là yếu điểm chung của mọi thuật toán máy học.
Yevgeniy Vorobeychik, phó giáo sư khoa học và công nghệ máy tính Đại học Vanderbilt (Mỹ), nhận định: "Mọi thuật toán đều có yếu điểm. Chúng ta đang sống trong thế giới đa chiều hết sức phức tạp trong khi các thuật toán chỉ tập trung vào một phần tương đối nhỏ của thế giới này".
Vorobeychik tin chắc rằng yếu điểm của AI sẽ bị kẻ xấu lợi dụng. Và, một số kẻ xấu thực sự đã hành động. Ví dụ như trường hợp các bộ lọc thư rác - những chương trình tự động chặn bất cứ email nào không rõ nguồn gốc.
Nhưng, kẻ xấu vẫn dễ dàng đánh lừa bằng cách sửa đổi cách viết một số từ nào đó - ví dụ như Vi@gra thay vì Viagra. Hoặc, hắn có thể che giấu những từ thường hay hiện trong những email bất hợp pháp như là "chúc mừng" hay "trúng giải". Hay, ghép vào danh sách các từ thường tìm thấy trong email hợp pháp như là "vui mừng" hay "tôi".
Cuộc chiến căng thẳng giữa hacker và AI
Trong trường hợp chiếc ô tô tự hành bị kẻ xấu đánh lừa bằng tấm sticker nhỏ dán trên cột đèn tín hiệu chỉ là một trong nhiều cách mà các chuyên gia an ninh AI tiên liệu được. Dữ liệu gây nhiễu loạn cũng cho phép hình ảnh khiêu dâm qua mặt được các bộ lọc kiểm tra nội dung an toàn. Bọn hacker cũng có thể chỉnh sửa mã các phần mềm độc hại để vượt qua hệ thống an ninh máy tính.
 |
| Hàng trăm hoặc hàng ngàn ví dụ mẫu (thường được dán nhãn cụ thể) được các nhà khoa học nạp vào máy tính để nó học hỏi cách nhận biết mọi thứ. |
Hay, kẻ lừa đảo có thể tìm cách tăng giá trị ngân phiếu. Về lý thuyết, hacker chỉ có thể gây nhiễu loạn bộ não AI nếu chúng có được bản sao thuật toán máy học mà chúng muốn đánh lừa. Đơn giản hơn, hacker sẽ tăng cường tấn công dồn dập bằng một loạt các phiên bản khác nhau của một email, hình ảnh hay bất cứ thứ gì cho đến khi một tập tin nào đó vượt qua được tường lửa.
Patrick McDaniel, giáo sư khoa học máy tính Đại học Bang Pennsylvania (Mỹ), cho rằng: "Kể từ khi ra đời, các hệ thống máy học đã bị thao tác. Trong khi đó, chúng ta vẫn không biết gì nhiều về các thủ đoạn của hacker".
Tuy nhiên, hành động gây nhiễu dữ liệu không chỉ có lợi cho đối tượng xấu mà còn hữu ích cho những ai muốn tránh né sự giám sát của công nghệ hiện đại. Daniel Lowd bình luận: "Nếu chính khách đối lập muốn tiến hành những hoạt động mà không bị theo dõi phát hiện bởi một loạt kỹ thuật do thám tự động hóa dựa vào máy học thì có lẽ hành động gây nhiễu loạn dữ liệu trở nên rất hữu ích".
Trong một dự án được công bố hồi tháng 10-2017, các nhà nghiên cứu Đại học Carnegie Mellon (Mỹ) cho biết họ đã chế tạo thành công cặp kính có khả năng đánh lừa hệ thống nhận dạng gương mặt gây nhầm lẫn giữa người này với người khác. Những công nghệ như thế hứa hẹn sẽ hữu ích cho những đối tượng muốn tránh né sự giám sát của chính quyền.
 |
| Về lý thuyết, hacker chỉ có thể gây nhiễu loạn bộ não AI nếu chúng có được bản sao thuật toán máy học mà chúng muốn đánh lừa. |
Daniel Lowd nhận định: "Để tránh bị đánh lừa, thuật toán phải được xây dựng hoàn toàn đúng trong mọi lúc và mọi nơi". Nhưng, cho dù chúng ta có tạo ra được hệ thống AI xuất sắc hơn con người đi chăng nữa thì cuối cùng thế giới này vẫn luôn tồn tại những trường hợp mập mờ mà ở đó câu trả lời đúng không dễ dàng có được.
Các thuật toán máy học thường được đánh giá theo độ chính xác của chúng. Một chương trình có khả năng nhận biết đúng đến 99% tất nhiên được đánh giá cao hơn chương trình chỉ đạt mức chính xác 90%. Tuy nhiên, hiện nay các chuyên gia máy tính lập luận rằng thuật toán cần được đánh giá theo khả năng chống chọi thành công một cuộc tấn công đánh lừa - càng kháng cự mạnh càng tốt hơn.
Một giải pháp khác có lẽ khả thi là giả lập các hành động tấn công đánh lừa để thuật toán máy học nhận biết và từ đó giúp cho hệ thống nhân tạo trở nên đáng tin cậy hơn. Tất nhiên, những cuộc tấn công giả lập cũng cần phải được thiết kế giống từng chi tiết những cuộc tấn công có thể xảy ra trong đời thực.
Theo lập luận của Patrick McDaniel, chúng ta cần cho phép con người can thiệp vào thuật toán trong những trường hợp cần thiết nhất để đánh giá độ chính xác. Một số "trợ lý thông minh cho phép con người can thiệp kiểm tra đồng thời chỉnh sửa những câu trả lời.
Trong khi đó, một số chuyên gia khác cho rằng sự kiểm tra của con người rất hữu ích trong các ứng dụng nhạy cảm như là quyết định của tòa án. Patrick McDaniel phát biểu: "Các hệ thống máy học là công cụ để lập luận. Nhưng, chúng ta không nên coi chúng như là những nhà tiên tri tài năng hoàn hảo".